


لقد غيرت مجموعات الذكاء الاصطناعي طريقة تدفق حركة المرور داخل مراكز البيانات بالكامل. في معظم الأوقات، تتحرك حركة المرور الآن من الشرق إلى الغرب بين وحدات معالجة الرسومات أثناء التدريب النموذجي ونقاط التفتيش، بدلاً من التحرك من الشمال إلى الجنوب بين التطبيقات والإنترنت. يشير هذا إلى حدوث تحول في مكان حدوث الاختناقات. وحدات المعالجة المركزية (CPUs)، التي كانت ذات يوم مسؤولة عن التغليف والتحكم في التدفق والأمن، أصبحت الآن على المسار الحرج. وهذا يضيف زمن الوصول والتنوع مما يجعل من الصعب استخدام وحدات معالجة الرسومات.
ونظرًا لحد الأداء هذا، تطورت DPU/SmartNIC من كونها أداة تسريع اختيارية لتصبح بنية تحتية ضرورية. وقال جنسن هوانغ، الرئيس التنفيذي لشركة NVIDIA، خلال GTC 2021: “مركز البيانات هو الوحدة الجديدة للحوسبة”.. “لا توجد طريقة للقيام بذلك على وحدة المعالجة المركزية. لذلك عليك إزالة حزمة الشبكة. أنت تريد إزالة حزمة الأمان، وتريد نقل حزمة معالجة البيانات وحركة البيانات.” جنسن هوانغ، مقابلة مع المنصة التالية. تدعي NVIDIA أن نسيج Spectrum-X Ethernet (الذي يشمل التحكم في الازدحام والتوجيه التكيفي والقياس عن بعد) يمكنه توفير ما يصل إلى 48٪ من عرض النطاق الترددي لقراءة تخزين أعلى لأحمال عمل الذكاء الاصطناعي.
أصبحت واجهة الشبكة الآن طبقة تعالج الأشياء. لم تعد مسألة النضج تتعلق بما إذا كان التفريغ ضروريًا أم لا، بل ما هي عمليات التفريغ التي توفر حاليًا عائد استثمار تشغيلي قابل للقياس.
حيث تصبح حركة مرور نسيج الذكاء الاصطناعي وموثوقيته أمرًا هامًا
تعمل أحمال عمل الذكاء الاصطناعي بشكل متزامن: عندما تواجه عقدة واحدة ازدحامًا، تنتظر جميع وحدات معالجة الرسومات في المجموعة. تشير Meta إلى أن تصادمات التدفق الناجمة عن التوجيه والتوزيع غير المتساوي لحركة المرور في عمليات نشر RoCE المبكرة “أدى إلى انخفاض أداء التدريب بما يصل إلى أكثر من 30%”، مما أدى إلى تغييرات في التوجيه والضبط الجماعي. هذه القضايا ليست معمارية بحتة. فهي تنشأ مباشرة من كيفية تصرف التدفقات بين الشرق والغرب على نطاق واسع.
لقد وفرت InfiniBand منذ فترة طويلة التحكم في التدفق على مستوى الارتباط على أساس الائتمان (لكل VL) لضمان التسليم بدون فقدان ومنع تجاوزات المخزن المؤقت، على سبيل المثال، آلية الأجهزة المضمنة في طبقة الارتباط. تتطور شبكة Ethernet على طول خطوط مماثلة من خلال اتحاد Ultra Ethernet (UEC): يقدم عمل Ultra Ethernet Transport (UET) الخاص به نقلًا لنقطة النهاية/المضيف، وإدارة الازدحام مسترشدة بالملاحظات في الوقت الفعلي، والتنسيق بين نقاط النهاية والمحولات، مما يؤدي بشكل واضح إلى نقل المزيد من معالجة الازدحام والقياس عن بعد إلى بطاقة واجهة الشبكة/نقطة النهاية.
يظل InfiniBand هو المعيار لسلوك النسيج الحتمي. تتطور أنسجة الذكاء الاصطناعي القائمة على شبكة إيثرنت بسرعة من خلال الابتكارات في UET وSmartNIC.
يجب على محترفي الشبكات تقييم قدرات السيليكون، وليس فقط سرعات الارتباط. يتم الآن تحديد الموثوقية من خلال القياس عن بعد والتحكم في الازدحام ودعم التفريغ على مستوى NIC/DPU.
اقرأ أيضًا: DevOps الأكثر ذكاءً مع Kite: AI يلتقي Kubernetes
نمط التفريغ: التغليف ومعالجة خطوط الأنابيب عديمة الحالة
تعتمد مجموعات الذكاء الاصطناعي على نطاق السحابة والمؤسسات على التراكبات مثل VXLAN وGENEVE لتقسيم حركة المرور عبر المستأجرين والمجالات. تقليديًا، يتم تشغيل مهام التغليف هذه على وحدة المعالجة المركزية (CPU).
تعمل وحدات DPU وSmartNIC على تفريغ التغليف والتجزئة ومطابقة التدفق مباشرة في خطوط أنابيب الأجهزة، مما يقلل من الارتعاش ويحرر دورات وحدة المعالجة المركزية. تقوم NVIDIA بتوثيق عمليات تفريغ أجهزة VXLAN على بطاقات NIC/وحدات DPU الخاصة بها وتدعي أن Spectrum-X يوفر مكاسب مادية من نسيج الذكاء الاصطناعي، بما في ذلك ما يصل إلى 48% من عرض النطاق الترددي لقراءة التخزين الأعلى في اختبارات الشركاء وزمن وصول أقل بأكثر من 4 مرات مقابل Ethernet التقليدية في قياس Supermicro.
يتم دعم إلغاء التحميل لـ VXLAN ومعالجة التدفق عديم الحالة عبر منصات NVIDIA BlueField وAMD Pensando Elba وMarvell OCTEON 10.
من منظور تنافسي:
- نفيديا يركز على التكامل بشكل وثيق مع Datacenter Infrastructure on-a-Chip (DOCA) لأحمال عمل الذكاء الاصطناعي المتسارعة بواسطة وحدة معالجة الرسومات.
- ايه ام دي بينساندو يوفر إمكانية برمجة P4 والتكامل مع Cisco Smart Switches.
- إنتل الاتحاد البرلماني الدولي يجلب تصميمات ثقيلة للذراع لبرمجة النقل.
لم يعد إلغاء تحميل التغليف مُحسِّنًا للأداء؛ فهو أساسي لسلوك نسيج الذكاء الاصطناعي الذي يمكن التنبؤ به.
نمط التفريغ: التشفير المضمن والأمن بين الشرق والغرب
نظرًا لأن نماذج الذكاء الاصطناعي تعبر الحدود السيادية وأصبحت المجموعات متعددة المستأجرين شائعة، فقد أصبح تشفير حركة المرور بين الشرق والغرب إلزاميًا. ومع ذلك، فإن تشفير حركة المرور هذه في وحدة المعالجة المركزية المضيفة يؤدي إلى فرض عقوبات على الأداء قابلة للقياس. في التحقق المشترك من VMware-6WIND-NVIDIA، قامت وحدات BlueField-2 DPUs بتفريغ IPsec لاختبار 25 جيجابت في الثانية (2×25 جيجابت في الثانية BlueField-2)، مما يدل على إنتاجية أعلى واستخدام أقل لوحدة المعالجة المركزية المضيفة لـ 6WIND vSecGW على vSphere 8.
الشكل: بفضل NVIDIA
تضع شركة Marvell وحدات OCTEON 10 DPU الخاصة بها لإلغاء تحميل الأمان المضمن في مراكز بيانات الذكاء الاصطناعي، مستشهدة بمسرعات التشفير المدمجة القادرة على توفير 400+ جيجابت في الثانية IPsec/TLS (مجموعة وسائط Marvell OCTEON 10 DPU Family)؛ تسلط الشركة الضوء أيضًا على الطلب المتزايد على البنية التحتية للذكاء الاصطناعي في اتصالاتها مع المستثمرين. يتحول إلغاء تحميل التشفير من اختياري إلى مطلوب حيث يصبح الذكاء الاصطناعي بنية تحتية منظمة.
نمط التفريغ: التجزئة الدقيقة وجدار الحماية الموزع
غالبًا ما يتم نشر خوادم GPU في مناطق عالية الثقة، ولكن لا تزال هناك مخاطر للحركة الجانبية، خاصة في البيئات التي بها العديد من المستأجرين أو عندما يتم الاستدلال على البنية التحتية المشتركة. يتم تكوين جدران الحماية التقليدية خارج وحدات معالجة الرسومات وتفرض حركة المرور بين الشرق والغرب من خلال نقاط الاختناق المركزية. ويساهم هذا الاختناق في زيادة زمن الوصول ويخلق نقاطًا عمياء في العمليات.
تتيح لك الآن وحدات DPU وSmartNIC إمكانية إعداد جدران الحماية L4 مباشرة على بطاقة NIC، وفرض السياسة من المصدر. قدمت Cisco سلسلة N9300 “Smart Switches”، التي تحتوي على وحدات DPU قابلة للبرمجة تضيف خدمات ذات حالة مباشرة إلى نسيج مركز البيانات لتسريع العمليات. تدعم وحدة BlueField DPU من NVIDIA بالمثل التجزئة الدقيقة، مما يسمح للمشغلين بتطبيق مبادئ Zero Trust على أحمال عمل وحدة معالجة الرسومات دون إشراك وحدة المعالجة المركزية المضيفة.
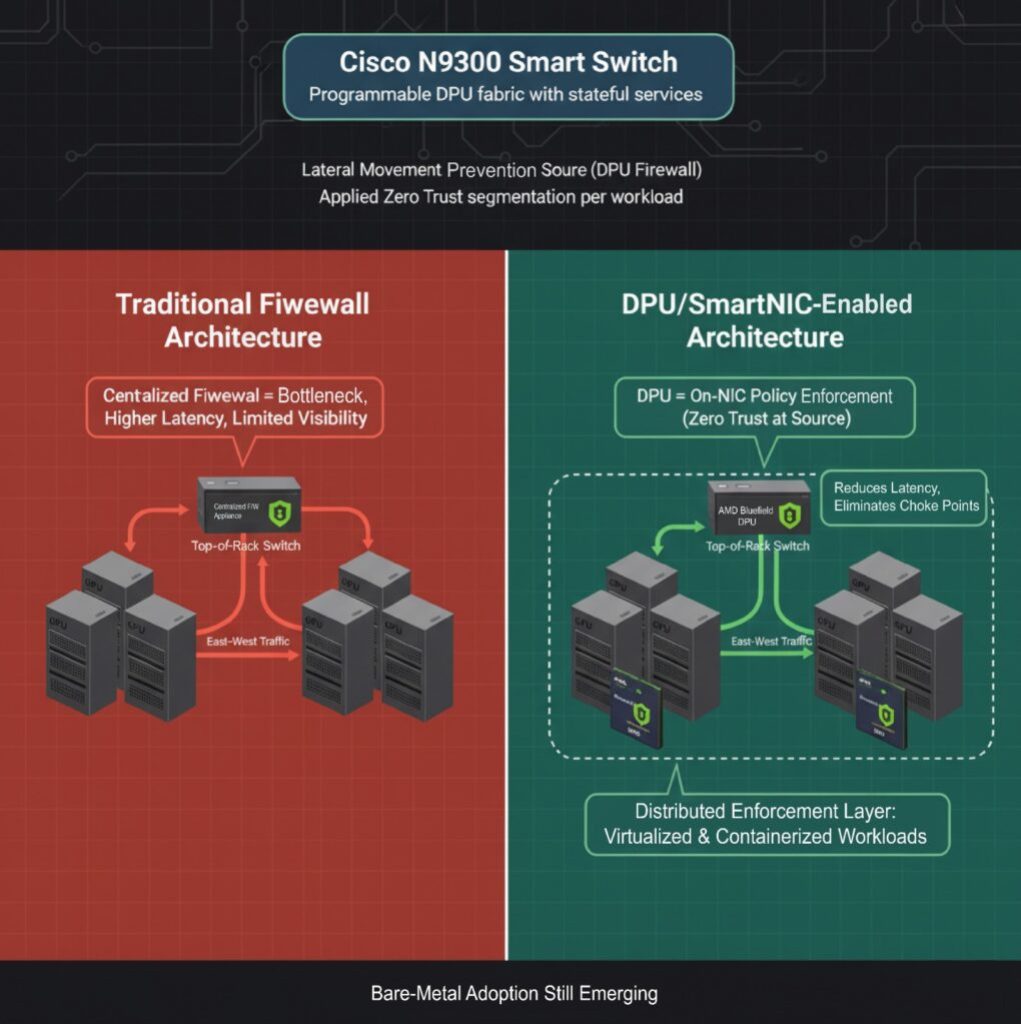
على الرغم من أن تفريغ جدار الحماية جاهز للإنتاج للبيئات الافتراضية والمحاوية، إلا أن تطبيقه في عمليات نشر نسيج الذكاء الاصطناعي المعدني لا يزال قيد التطوير.
يكتسب مهندسو الشبكات نقطة تنفيذ جديدة داخل الخادم نفسه. يكتسب نمط التفريغ هذا زخمًا في عمليات نشر الذكاء الاصطناعي الخاضعة للتنظيم والسيادة حيث يكون العزل بين الشرق والغرب مطلوبًا.
اقرأ أيضًا: Agentic AI vs AI Agents: الاختلافات الرئيسية والتأثير على مستقبل الذكاء الاصطناعي
لمحة سريعة عن الحالة: عمليات نسيج Ethernet AI في الإنتاج
للتغلب على عدم استقرار النسيج، شاركت Meta في تصميم طبقة النقل والمكتبة الجماعية، وتنفيذ هندسة حركة مرور ECMP المحسنة، وتوسيع نطاق قائمة الانتظار، ونموذج قبول يعتمد على جهاز الاستقبال. أدت هذه التغييرات إلى تحسن بنسبة تصل إلى 40% في زمن وصول إكمال AllReduce، مما يوضح أن أداء النسيج يتم تحديده الآن من خلال منطق النقل في بطاقة NIC بقدر ما يتم تحديده من خلال بنية المحول.
في مثال آخر، من خلال التحقق المشترك من VMware – 6WIND – NVIDIA، قامت وحدات DPU BlueField-2 بإلغاء تحميل IPsec لـ 6WIND vSecGW على vSphere 8. استهدف الإعداد المعملي (المحدود بمنافذ BlueField-2 المزدوجة 25 جيجابت) وأظهر على الأقل 25 جيجابت في الثانية من إنتاجية IPsec المجمعة وأظهر أن التفريغ أدى إلى زيادة الإنتاجية وتحسين استجابة التطبيق، مع تحرير نوى وحدة المعالجة المركزية المضيفة.
عمليات النشر الحقيقية تؤكد صحة مكاسب الأداء. ومع ذلك، تظل المعايير المستقلة التي تقارن بين البائعين محدودة. يجب على مهندسي الشبكات تقييم مطالبات البائعين من خلال عدسة أدلة النشر المنشورة، بدلاً من الاعتماد على أرقام التسويق.
مشهد المشتري: نضج السيليكون وSDK
يتم تحويل المشهد التنافسي من خلال استراتيجيات DPU وSmartNIC. يسلط الجدول التالي الضوء على الاعتبارات والاختلافات الرئيسية بين البائعين المختلفين.
| بائع | التفاضل | نضج | الاعتبارات الرئيسية |
| نفيديا | تكامل محكم مع وحدات معالجة الرسومات وDOCA SDK والقياس عن بعد المتقدم | عالي | أعلى أداء؛ يعد قفل النظام البيئي مصدر قلق |
| ايه ام دي بينساندو | خط أنابيب قائم على P4، وتكامل Cisco | عالي | قوي في عمليات النشر المؤسسية والمختلطة |
| إنتل الاتحاد البرلماني الدولي | النقل القابل للبرمجة، وتسريع التشفير | الناشئة | الطرح المتوقع في عام 2025؛ مدعومة بسجل نشر Google |
| مارفيل أوكتيون | كفاءة في استخدام الطاقة، وتفريغ مركزي للتخزين | واسطة | القوة في الحافة والتخزين المصنف AI |
يمنح المشترون الأولوية لأكثر من السرعات والأعلاف الأولية. تؤكد Omdia على أن العمليات الفعالة تتوقف الآن على الأتمتة المعتمدة على الذكاء الاصطناعي والقياس عن بعد القابل للتنفيذ، وليس فقط معدلات الارتباط الأعلى.
يجب أن تتماشى قرارات الشراء ليس فقط مع أهداف الأداء ولكن مع نضج خريطة طريق SDK ومخاطر قفل النظام الأساسي على المدى الطويل.
الخيارات التنافسية والمعمارية: ما يجب أن يقرره المشغلون
مع انتقال أنسجة الذكاء الاصطناعي من النشر المبكر إلى الإنتاج على نطاق واسع، يواجه قادة البنية التحتية العديد من القرارات الإستراتيجية التي ستشكل التكلفة والأداء والمخاطر التشغيلية لسنوات قادمة.
DPU مقابل SuperNIC مقابل High-End NIC
توفر لك وحدات DPU نوى الذراع وكتل التشفير وإمكانيات إلغاء تحميل التخزين/الشبكة. وهي تعمل بشكل أفضل في بيئات الذكاء الاصطناعي التي تضم مستأجرين متعددين، أو خاضعة للتنظيم، أو حساسة للأمان. تم تصميم بطاقات SuperNIC، مثل محولات Spectrum-X من NVIDIA، للعمل مع المحولات ذات زمن الوصول المنخفض للغاية والتكامل العميق للقياس عن بعد، ولكنها تفتقر إلى معالجات للأغراض العامة.
قد تستمر بطاقات NIC المتطورة (بدون إمكانات التفريغ) في خدمة مجموعات الذكاء الاصطناعي ذات المستأجر الواحد أو صغيرة الحجم، ولكنها تفتقر إلى القدرة على الاستمرار على المدى الطويل لأنسجة الذكاء الاصطناعي متعددة القرون.
Ethernet مقابل InfiniBand لأقمشة الذكاء الاصطناعي
لا يزال InfiniBand هو الأفضل في التحكم في الازدحام وزمن الوصول المتوقع. ومع ذلك، سرعان ما أصبحت Ethernet أكثر شيوعًا حيث قام البائعون بتوحيد تقنية Ultra Ethernet Transport وإضافة إلغاء تحميل SmartNIC/DPU. يعد InfiniBand هو الخيار الأفضل لعمليات النشر واسعة النطاق حيث تقبل تقييد البائع.
“عندما بدأنا تغطيتنا لشبكات AI الخلفية لأول مرة في أواخر عام 2023، كانت InfiniBand تهيمن على السوق، حيث استحوذت على أكثر من 80 بالمائة من الحصة… ومع انتقال الصناعة إلى 800 جيجابت في الثانية وما بعدها، نعتقد أن Ethernet أصبحت الآن في وضع قوي يمكنها من تجاوز InfiniBand في عمليات النشر عالية الأداء هذه.” سامح بوجلبان، نائب رئيس مجموعة Dell’Oro.
SDK والتحكم في النظام البيئي
أصبحت سيطرة البائعين على النظم الإيكولوجية للبرمجيات عامل تمييز رئيسي. يمثل كل من NVIDIA DOCA وإطار العمل المستند إلى AMD’s P4 وIntel’s IPU SDK مسارات تطوير متباينة. إن اختيار بائع اليوم يعني بشكل فعال اختيار نموذج برمجة واستراتيجية تكامل طويلة المدى.
اقرأ أيضًا: كيف يمكن لروبوتات الدردشة المدعمة بالذكاء الاصطناعي المساعدة في تبسيط عمليات عملك؟
عندما تخرج أقلام الرصاص وما يجب مشاهدته بعد ذلك
لم يعد يتم وضع وحدات DPU وSmartNIC كعناصر تمكين مستقبلية. لقد أصبحت البنية التحتية المطلوبة للشبكات على نطاق الذكاء الاصطناعي. تكون حالة العمل أكثر شفافية في المجموعات حيث:
- تهيمن حركة المرور بين الشرق والغرب
- يتأثر استخدام وحدة معالجة الرسومات (GPU) بازدحام microburst
- تتطلب المتطلبات التنظيمية أو متطلبات المستأجرين المتعددين التشفير أو العزل
- تتداخل حركة مرور التخزين مع أداء الحساب
أبلغ المتبنون الأوائل عن عائد استثمار قابل للقياس. كشفت NVIDIA عن تحسين استخدام وحدة معالجة الرسومات وزيادة بنسبة 48% في إنتاجية التخزين المستدامة في عمليات نشر Spectrum-X التي تجمع بين القياس عن بعد وتفريغ الازدحام. وفي الوقت نفسه، أبلغت Marvell وAMD عن ارتفاع معدلات إرفاق وحدات DPU في تصميم الذكاء الاصطناعي حيث يطلب المشغلون استقلالية مسار البيانات من وحدة المعالجة المركزية المضيفة.
على مدار الـ 12 شهرًا القادمة، يجب على متخصصي الشبكات مراقبة ما يلي عن كثب:
- خريطة طريق NVIDIA لتحسينات BlueField-4 وSuperNIC
- تم دمج وحدات DPU Salina من AMD Pensando في محولات Cisco الذكية
- مواصفات UEC 1.0 والجداول الزمنية لاعتماد البائع
- أول عمليات نشر إنتاجية من Intel لوحدة E2200 IPU
- معايير مستقلة تقارن أداء Ethernet Ultra Fabric مقابل أداء InfiniBand في ظل الأحمال الجماعية للذكاء الاصطناعي
تتوقف اقتصاديات شبكات الذكاء الاصطناعي الآن على مكان حدوث المعالجة. يجري التحول الاستراتيجي من البنى التي تركز على وحدة المعالجة المركزية (CPU) إلى البنى التحتية حيث تحدد وحدات DPU وSmartNIC الأداء والموثوقية والأمان على نطاق واسع.



